AI는 PDF를 제대로 못 읽는다
— 지금 당장 Markdown으로 바꿔야 하는 이유
국가AI전략위원회가 공공문서를 마크다운으로 전환하기 시작했다. 이건 단순한 형식 변경이 아니다. AI 시대의 정보 격차가 문서 형식에서 시작된다는 신호다.
PDF와 HWP 문서는 사람 눈에 보기 좋게 설계됐지만, AI가 구조를 파악하기에는 최악의 형식입니다. Markdown은 최소한의 기호로 문서 계층을 표현해 AI가 정확하게 읽을 수 있는 구조를 제공합니다. 대한민국 국가AI전략위원회도 이 문제를 인지하고 2026년 3월부터 정책 문서를 Markdown으로 전환하기 시작했으며, IMLAB은 PDF → Markdown 변환 서비스를 공개했습니다.
- 1PDF·HWP는 시각적 레이아웃 중심 — AI가 문단 구조를 정확히 인식하지 못한다
- 2Markdown은 AI 학습 데이터의 표준 형식 — 구조 손실 없이 처리 가능하다
- 3국가AI전략위원회가 2026년 3월 공공문서 마크다운 전환 공식 선언
- 4IMLAB의 변환 서비스로 누구나 즉시 적용 가능하다
문서 형식이 AI 성능을 결정한다
AI에게 문서를 주고 분석을 시켜본 경험이 있다면 한 번쯤 이런 상황을 겪었을 것이다. 내용은 분명히 있는데 AI가 엉뚱한 답을 내놓거나, 표 안의 데이터를 잘못 해석하거나, 문서 구조를 완전히 무시한 채 응답한다. 이것은 AI 모델의 한계가 아니다. 문서 형식의 문제다.
LLM(거대언어모델)은 텍스트 구조를 이해하며 작동한다. 제목이 제목처럼, 목록이 목록처럼, 표가 표처럼 인식되어야 정확한 추론이 가능하다. 그런데 우리가 일상적으로 다루는 PDF와 HWP 파일은 그 구조 정보를 시각적 레이아웃 안에 숨겨버린다.
- ✕글꼴·자간·여백으로 구조 표현
- ✕제목인지 본문인지 문맥 추론 필요
- ✕표·이미지 내 텍스트 추출 불안정
- ✕복사 붙여넣기 시 서식 완전 소실
- ✕AI 학습 데이터로 활용 어려움
- ✓# 기호만으로 제목 계층 명시
- ✓구조가 텍스트에 직접 인코딩됨
- ✓표·코드블록 표준 문법으로 처리
- ✓플랫폼 무관하게 구조 100% 유지
- ✓AI 학습 데이터의 국제 표준 형식
PDF의 어디가 문제인가 — 기술적으로 파헤치기
PDF(Portable Document Format)는 1993년 어도비가 만든 형식이다. 목적은 하나였다. “어떤 기기에서 열어도 똑같이 보이게.” 즉, PDF는 처음부터 사람의 눈을 위해 설계됐다. AI를 위한 설계가 아니다.
-
레이아웃 기반 구조제목이 왜 제목인지 PDF 내부에는 명시되지 않는다. “글자 크기가 크고 굵으니까 제목이겠지”를 AI가 추론해야 한다. 추론이 틀리면 구조 전체가 무너진다.
-
표와 이미지 처리 한계PDF 속 표는 텍스트가 좌표 기반으로 배치된 것이다. 행과 열의 관계를 AI가 픽셀 위치로 추론해야 하기 때문에 오류율이 높고, 합산·비교 분석에서 실수가 잦다.
-
HWP의 한국식 편집 문화HWP는 한글 특유의 글꼴 체계, 문단 기호, 기호표 등 독자적 편집 요소를 사용한다. 국제 표준 파서가 없어 AI 도구 대부분이 지원하지 않거나 불완전하게 처리한다.
-
컨텍스트 분절PDF를 텍스트로 추출하면 페이지 단위로 잘리면서 하나의 문단이 두 페이지에 걸쳐 분절되는 경우가 생긴다. LLM은 컨텍스트가 끊기면 의미를 잘못 연결한다.
실제 차이를 코드로 비교하면
2024년도 사업 계획서 1. 개요 및 목적 본 사업은 지역 농산물 부산물 의 자원 순환을 통해... (계속) 그림 1-1. 사업 구조도 [이미지 미추출] 2.추진 일정 1분기2분기3분기4분기 기획 실행 중간점검완료
# 2024년도 사업 계획서 ## 1. 개요 및 목적 본 사업은 지역 농산물 부산물의 자원 순환을 통해... (계속) > 그림 1-1: 사업 구조도 참고 ## 2. 추진 일정 | 구분 | 1분기 | 2분기 | 3분기 | 4분기 | |------|------|------|------|------| | 단계 | 기획 | 실행 | 점검 | 완료 |
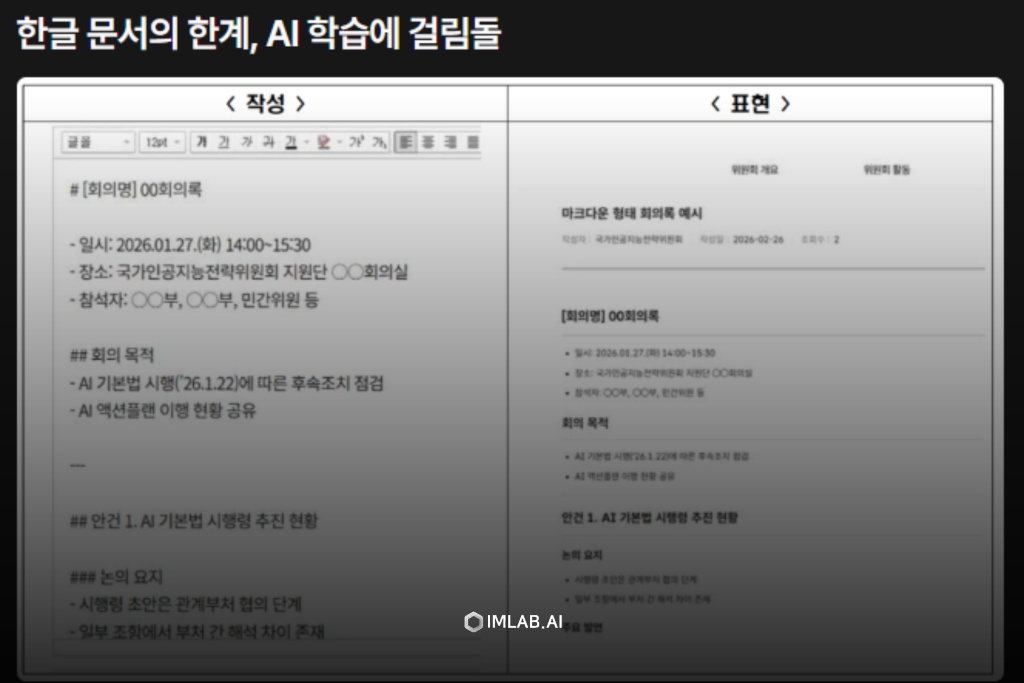
왼쪽은 AI가 “2. 추진 일정” 아래 표가 있다는 사실을 인식하기 어렵다. 오른쪽은 제목 계층, 인용, 표 구조가 모두 기호로 명시되어 있어 AI가 즉각적으로 파악한다.
대한민국 정부도 인정했다 — 공공문서 마크다운 전환 선언
이 문제는 개발자들의 불만 수준을 넘어 국가 정책 과제가 됐다. 2026년 3월 5일, 대한민국 국가인공지능전략위원회가 공식 발표했다.
국가인공지능전략위원회가 분과별 회의와 토론 결과를 마크다운 형식(.md)으로 작성·관리하고, 위원회 누리집을 통해 공개한다고 밝혔다. 기존 한글(HWP) 문서는 글꼴·자간·기호표 등 다양한 편집 요소로 인해 AI가 문장과 문단 구조를 정확히 인식하는 데 어려움이 있다는 문제의식에서 추진됐다.
“AI 시대에는 정책 내용뿐 아니라 정책이 축적되고 관리되는 방식 자체를 혁신하는 것이 중요하다. 이번 문서 체계 전환은 정부가 AI를 활용하는 방식과 일하는 문화를 바꾸는 출발점이 될 것이다.”
— 임문영 국가AI전략위 상근 부위원장
위원회가 특히 주목한 것은 두 가지였다. 첫째, 정책 문서는 공적 의사결정이 축적된 고품질 데이터라는 점. 둘째, Markdown은 국제적으로 AI 학습 데이터의 표준 형식으로 쓰이기 때문에 민간 기업의 AI 모델 개발과 서비스 혁신에도 직접 활용될 수 있다는 점이다.
이 발표는 단순히 “문서 형식 바꾸기”가 아니다. 공공 데이터를 AI 생태계의 연료로 전환하겠다는 국가 전략이다. 공공문서가 Markdown으로 쌓이기 시작하면 한국어 AI 학습 데이터의 품질이 근본적으로 달라진다.
Markdown이 AI 친화적인 이유 — 구조적으로 설명하면
Markdown은 2004년 존 그루버(John Gruber)가 만든 경량 마크업 언어다. 핵심 철학은 하나였다. “읽기 쉬운 텍스트 형식으로도 구조화된 문서를 만들 수 있어야 한다.”
-
구조가 텍스트에 인코딩된다# 제목, ## 소제목, **강조**, | 표 | 모두 기호 자체가 의미를 가진다. AI가 별도의 레이아웃 추론 없이 구조를 즉각 파악한다.
-
AI 학습 데이터의 국제 표준GitHub, Wikipedia, Hugging Face 등 주요 AI 학습 소스들이 Markdown 기반이다. LLM 자체가 Markdown 구조에 최적화되어 학습되어 있다.
-
플랫폼 독립적Notion, Obsidian, VS Code, GitHub, Confluence 어디서도 동일하게 렌더링된다. 워드프레스·Ghost 블로그에도 바로 적용 가능하다.
-
RAG 파이프라인 성능 향상AI 에이전트·RAG(검색증강생성) 시스템에서 문서를 청크(chunk)로 분할할 때, Markdown의 헤더 구조를 기준으로 분할하면 의미 단위가 보존되어 검색 정확도가 높아진다.
IMLAB의 답 — PDF → Markdown 변환 서비스
이 문제를 해결하기 위해 IMLAB은 AI 기반 PDF → Markdown 변환 서비스를 공개했다. 단순 텍스트 추출이 아니라, 문서 구조를 AI가 이해하며 Markdown 계층 구조로 재구성하는 방식이다.
어떤 상황에서 사용하면 되나
-
기업 내부 문서의 AI 활용사내 PDF 보고서, 제안서, 매뉴얼을 Markdown으로 변환해 AI 에이전트의 지식 베이스(Knowledge Base)로 구축할 때
-
공공기관 문서 디지털 전환정부 발주 사업 공고문, 지침서, 정책 보고서를 AI가 읽을 수 있는 형식으로 변환해 입찰 분석·정책 모니터링 자동화에 활용할 때
-
연구·교육 자료 정리논문, 연구 보고서, 강의 자료를 Markdown으로 변환해 AI 요약·질의응답·번역 파이프라인에 연결할 때
-
콘텐츠 워크플로우 자동화PDF 리포트를 Markdown으로 변환 후 → 워드프레스 포스팅, 뉴스레터, SNS 콘텐츠로 AI가 재가공하는 자동화 파이프라인 구성 시
자주 묻는 질문
핵심 요약표
| 구분 | PDF / HWP | Markdown | AI 활용 시 차이 |
|---|---|---|---|
| 구조 표현 | 글꼴 크기·위치로 암묵적 표현 | #, ##, **로 명시적 표현 | Markdown이 구조 인식 오류 0에 수렴 |
| 표 처리 | 좌표 기반 배치 → 추출 불안정 | | 기호로 행/열 명확히 정의 | AI 분석 정확도 대폭 향상 |
| 호환성 | 전용 뷰어 필요, 버전 의존 | 일반 텍스트 편집기에서 모두 열림 | 어떤 AI 도구에도 바로 사용 가능 |
| 공공정책 | 기존 정부·공공기관 표준 | 국가AI전략위 2026.03 전환 선언 | 공공 데이터 AI 활용 생태계 확장 |
| RAG 연동 | 청크 분할 시 의미 단위 파괴 | 헤더 기준 의미 단위 분할 가능 | 검색 정확도·응답 품질 향상 |
| IMLAB 서비스 | AI 기반 PDF → Markdown 자동 변환 | 즉시 AI 파이프라인 적용 가능 | |